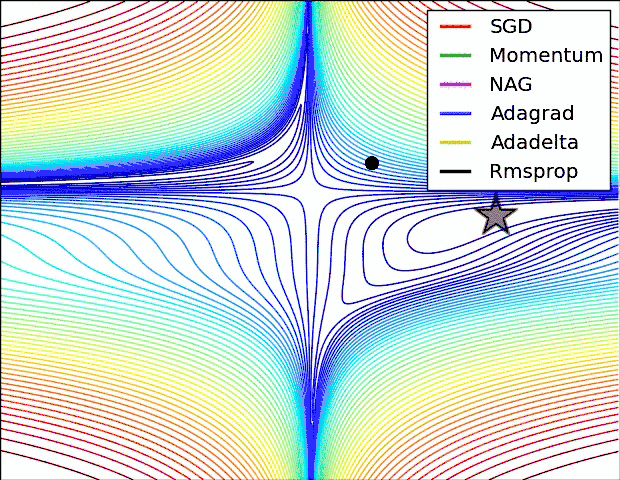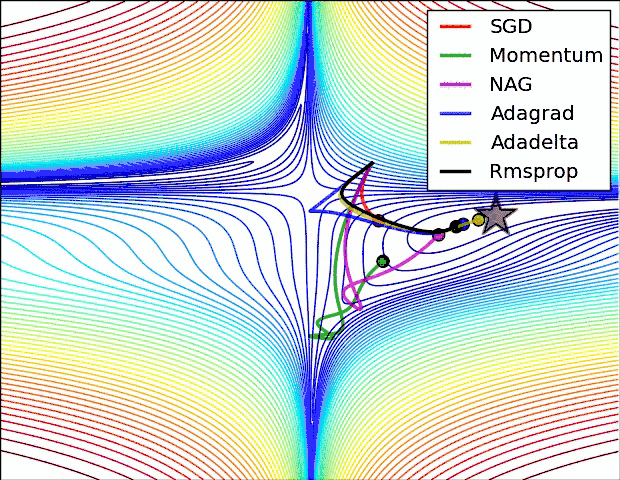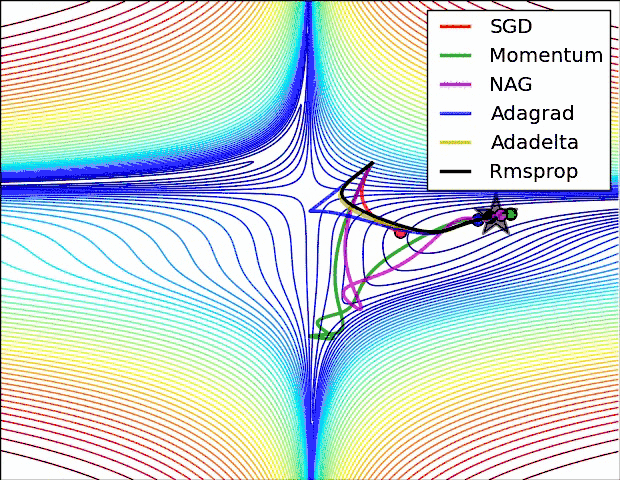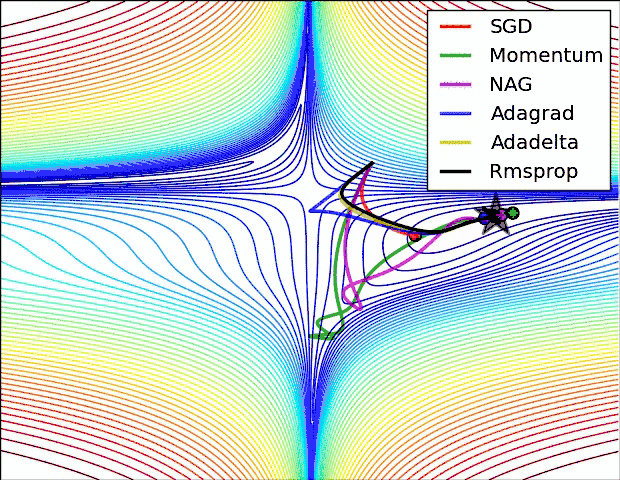

就是对梯度进行优化更新的,这样不仅能使模型找到最优点,而且能大大提升模型收敛速度,当然不同的优化器找到的最优点可能不同,有可能使局部最优点,有可能使全局最优点,这个是决定模型好坏的重要因素之一,所以优化器怎么选对模型的好坏起着重要的作用。
1、梯度下降算法:
梯度下降最常见的三种变形 BGD,SGD,MBGD,这三种形式的区别就是取决于我们用多少数据来计算目标函数的梯度
Ⅰ.BGD【Batch Gradient Descent,批量梯度下降】:采用整个训练集的数据来计算 cost function 对参数的梯度:

BGD缺点:这种方法是在一次更新中,就对整个数据集计算梯度,所以计算起来非常慢,而且不能投入新数据实时更新模型。
Ⅱ.SGD【Stochastic Gradient Descent,随机梯度下降】:每次更新时对每个样本进行梯度更新,对于很大的数据集来说,可能会有相似的样本,这样 BGD 在计算梯度时会出现冗余,而SGD就没有冗余,而且比较快,并且可以新增样本。

SGD缺点:1.SGD 因为更新比较频繁,会造成 cost function 有严重的震荡;2.BGD 可以收敛到局部极小值,当然 SGD 的震荡可能会跳到更好的局部极小值处;3.当我们稍微减小 learning rate,SGD 和 BGD 的收敛性是一样的。
Ⅲ.MBGD【Mini-Batch Gradient Descent小批量梯度下降】: 每一次利用一小批样本即n个样本进行计算,这样它可以降低参数更新时的方差,收敛更稳定,另一方面可以充分地利用深度学习库中高度优化的矩阵操作来进行更有效的梯度计算。

MBGD缺点:1.不能保证很好的收敛性,learning rate 如果选择的太小,收敛速度会很慢,如果太大,loss function 就会在极小值处不停地震荡甚至偏离。
Ⅳ.Momentum【动量】:SGD 在 ravines 的情况下容易被困s住,ravines就是曲面的一个方向比另一个方向更陡,这时 SGD 会发生震荡而迟迟不能接近极小值:
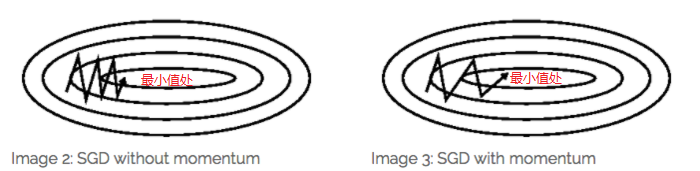
Momentum SGD的更新公式为加了一个初始动量,即每次更新梯度时当前梯度需加上前面梯度*γ:
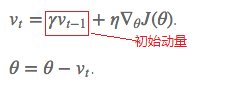
让我们想象下,当我们将一个小球从山上滚下来时,没有阻力的话,它的动量会越来越大,但是如果遇到了阻力,速度就会变小。
加入的这一项,可以使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡【超参数设定值:一般γ取值0.9左右】。
Ⅴ.NAG【Nesterov Accelerated Gradient,nesterov加速梯度】:
用 θ?γv_t?1 来近似当做参数下一步会变成的值,则在计算梯度时,不是在当前位置,而是未来的位置上【 超参数设定值: 一般 γ 仍取值 0.9 左右】:

Nesterov与Momentum进行比较:

蓝色是 Momentum 的过程,会先计算当前的梯度,然后在更新后的累积梯度后会有一个大的跳跃。
而NAG会先在前一步的累积梯度上(brown vector)有一个大的跳跃,然后衡量一下梯度做一下修正(red vector),这种预期的更新可以避免我们走的太快,在更新梯度时顺应 loss function 的梯度来调整速度,并且可对SGD进行加速。
2.Adagrad优化算法:
通过以往的梯度自适应更新学习率,不同的参数θi具有不同的学习率。Adagrad 对常出现的特征进行小幅度更新,不常出现的特征进行大幅度的更新,就可以对低频的参数做较大的更新,对高频的做较小的更新,也因此,对于稀疏的数据它的表现很好,很好地提高了 SGD 的鲁棒性【一般η选取0.01】

Adagrad算法缺点:分母会不断积累,这样学习率就会收缩并最终会变得非常小,最终会加快到梯度饱和。
3.RMSprop优化算法:
这个算法是为了解决 Adagrad 学习率急剧下降问题的,对 Adagrad 的改进,是一种自适应学习率方法,使用的是指数加权平均,旨在消除梯度下降中的摆动,与Momentum的效果一样,某一维度的导数比较大,则指数加权平均就大,某一维度的导数比较小,则其指数加权平均就小,这样就保证了各维度导数都在一个量级,进而减少了摆动。其中图片公式第一行E在t时刻的值依赖于前一时刻的平均和当前的梯度,这里γ表示前一时刻平均与当前梯度的占比。允许使用一个更大的学习率η【建议设定γ为0.9, 学习率η为 0.001】
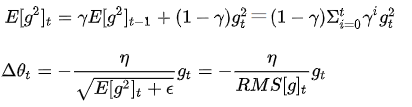
RMSprop算法缺点:仍然依赖于全局的学习率η,需要手动初始化η
4.Adadelta优化算法:
这个算法从内容上看可以说是RMSprop算法的一个改进,指在消除依赖全局学习率,将学习率η换成了 RMS(Δθ),这样的话,我们甚至都不需要提前设定学习率了:

5.Adam【Adaptive Moment Estimation】优化算法:
这个算法是另一种计算每个参数的自适应学习率的方法。相当于 RMSprop+Momentum
除了像Adadelta和RMSprop一样存储了过去梯度的平方vt的指数衰减平均值,也像momentum一样保持了过去梯度mt的指数衰减平均值。β是过去和当前的占比:
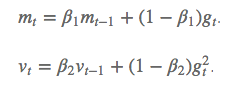
如果 mt 和 vt 被初始化为 0 向量,那它们就会向 0 偏置,所以做了偏差校正,通过计算偏差校正后的 mt 和 vt 来抵消这些偏差:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
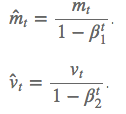
因此该算法的梯度更新规则为【建议 β1 = 0.9,β2 = 0.999,? = 10e?8】:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
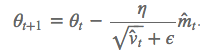
实践表明,Adam比其他适应性学习方法效果要好,下面是以上优化算法的梯度更新路线图: